
Trí tuệ nhân tạo, đặc biệt là nhánh machine learning (học máy), đang âm thầm làm lại gần như toàn bộ “bộ đồ nghề” của giới địa chấn học: từ việc phát hiện động đất, vẽ lại bản đồ đứt gãy dưới lòng đất, đến cải thiện các bản dự báo dư chấn sau những trận động đất lớn.
Khi trận động đất mạnh nhất trong hơn một thập kỷ làm rung chuyển bán đảo Kamchatka hẻo lánh của Nga vào tháng 7 vừa rồi, các nhà địa chấn trên khắp thế giới biết chuyện chỉ sau vài khoảnh khắc. Với bất kỳ trận động đất lớn hay nhỏ nào, mạng lưới cảm biến toàn cầu sẽ ghi nhận dao động, gửi dữ liệu về cho các cơ quan nghiên cứu để phân tích nhanh và phát đi cảnh báo.
Bây giờ, trí tuệ nhân tạo đang chuẩn bị tăng tốc gần như mọi khâu trong chu trình đó – và thậm chí còn đang buộc các nhà khoa học phải xem lại tận gốc cách một trận động đất thực sự diễn ra như thế nào.
Nhờ học máy, một số nhóm nghiên cứu đã phát hiện được tới… hàng triệu trận động đất nhỏ tí xíu mà trước đây chưa từng được nhận diện trong dữ liệu từ các khu vực có hoạt động địa chấn mạnh. Những “siêu cơ sở dữ liệu” mới này giúp họ hiểu rõ hơn cấu trúc các đứt gãy – nơi động đất xảy ra – và từ đó đánh giá tốt hơn nguy cơ trong tương lai. Một số nhóm khác thì dùng học máy để cải thiện các dự báo dư chấn sau những trận động đất lớn, giúp ước lượng xem trong những giờ, những ngày tiếp theo mặt đất sẽ còn rung chuyển tới mức nào.
Xa hơn nữa, các nhà khoa học kỳ vọng khả năng “nhai” dữ liệu khổng lồ và tự tìm quy luật của học máy sẽ giúp hé lộ những bí ẩn lâu năm về động đất – chẳng hạn như điều gì thực sự diễn ra trong những giây đầu tiên đầy tàn phá của một trận động đất lớn.
“Machine learning đã mở ra một cánh cửa hoàn toàn mới,” nhà địa chấn học Mostafa Mousavi (ĐH Harvard) nói.

Trái đất rung chuyển, dữ liệu nổ tung
Động đất xảy ra khi ứng suất trong lòng đất tích tụ đến mức đá không chịu nổi nữa. Ở những nơi như đứt gãy San Andreas (California), hai mảng vỏ Trái đất trượt ngang qua nhau, ma sát làm ứng suất tăng dần. Tới một ngưỡng nào đó, mảng đứt gãy “đứt” – đá bị phá vỡ, năng lượng địa chấn tỏa ra dạng sóng, lan truyền và làm mặt đất rung lên.
Năng lượng này được ghi lại bởi các máy địa chấn và những thiết bị khác. Ở những vùng hoạt động địa chấn mạnh như California hay Nhật Bản, người ta đặt rất nhiều cảm biến. Dữ liệu từ đó đổ vào các hệ thống quốc gia và quốc tế để theo dõi động đất và phát cảnh báo.
Trong vài năm gần đây, lượng dữ liệu tăng vọt do người ta liên tục nghĩ ra cách mới để “nghe” Trái đất rung: như tận dụng tín hiệu địa chấn đi qua cáp quang, hay dùng cảm biến gia tốc trong điện thoại thông minh để xây dựng mạng cảnh báo động đất dựa trên smartphone.
Cách đây chỉ một, hai thập kỷ, phần lớn dữ liệu này vẫn được phân tích thủ công. Các nhà địa chấn phải ngồi nhìn từng bản ghi, càng nhanh càng tốt, khi dữ liệu dồn dập tuôn về từ mạng lưới trạm đo. Ngày nay, khối lượng dữ liệu đã quá lớn, con người không thể xử lý kịp nữa.
“Bây giờ gần như cách duy nhất để xử lý dữ liệu địa chấn là tự động hóa,” Mousavi nói. Năm 2023, ông đồng tác giả một bài tổng quan về học máy trong địa chấn học đăng trên Annual Review of Earth and Planetary Sciences.
“Phase picking”: công việc tẻ nhạt nay giao cho AI
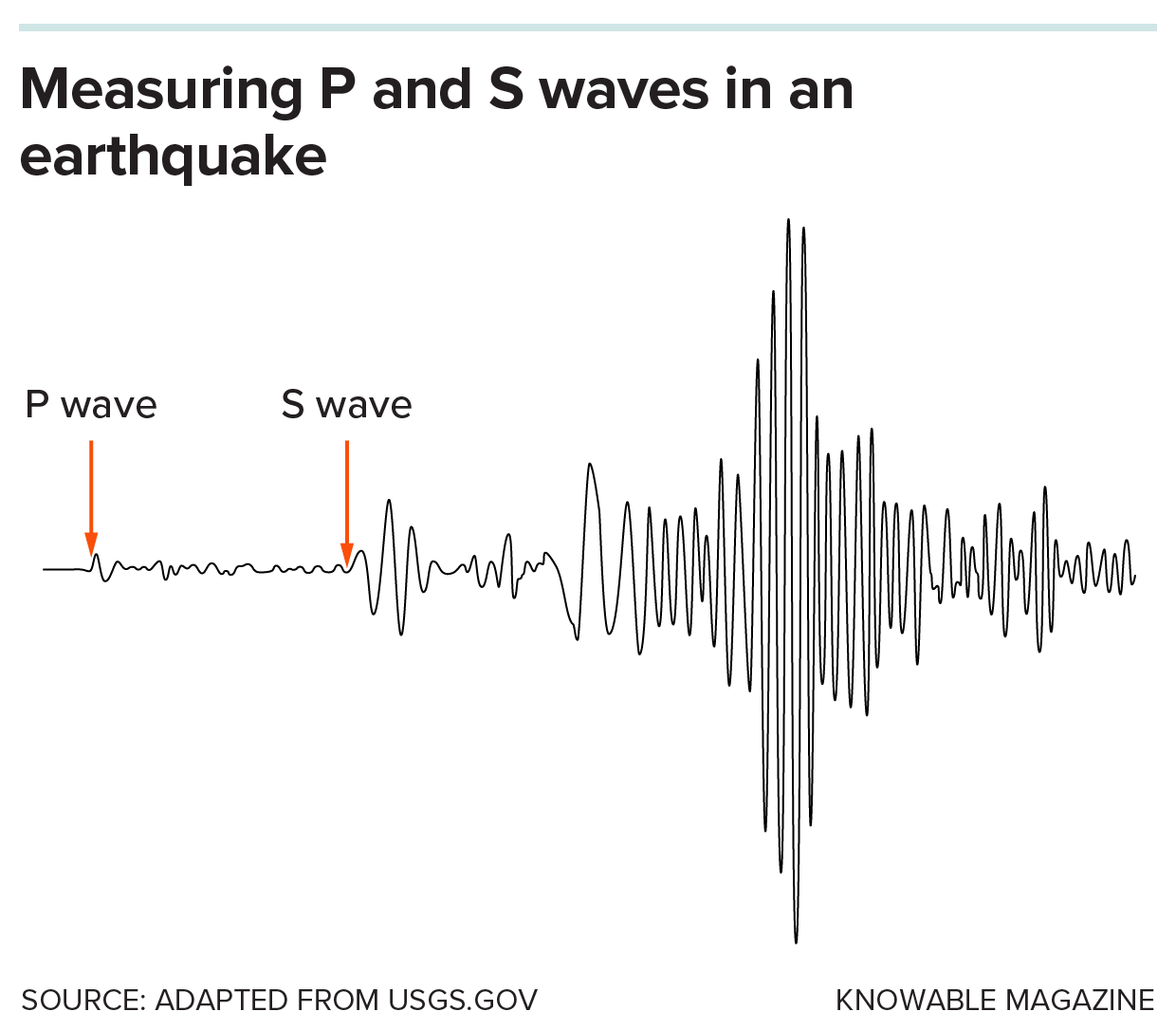
Một trong những ứng dụng phổ biến nhất của học máy trong địa chấn học là “phase picking” – xác định thời điểm sóng địa chấn tới trạm đo.
Khi động đất xảy ra, nó sinh ra hai loại sóng chính:
- Sóng P (primary wave) – đến trước, làm đất nén – giãn theo phương truyền sóng
- Sóng S (secondary wave) – đến sau, làm đất rung ngang
Trên biểu đồ địa chấn, hai loại sóng này hiện lên như những đoạn “ngoằn ngoèo” khác nhau. Trước đây, các nhà địa chấn sẽ nhìn bản ghi và dùng kinh nghiệm để đánh dấu: “Đây là lúc sóng P bắt đầu”, “Đây là lúc sóng S bắt đầu”.
Việc chọn đúng, chọn chính xác thời điểm đó cực kỳ quan trọng: nó quyết định việc tính được tâm chấn nằm ở đâu, độ sâu bao nhiêu, và nhiều thông số khác. Nhưng phase picking bằng tay rất tốn thời gian.
Vài năm trở lại đây, các thuật toán học máy đã được dùng để làm việc này nhanh hơn con người rất nhiều. Có nhiều phương pháp tự động khác nhau, nhưng các mô hình học máy – được “huấn luyện” trên kho dữ liệu khổng lồ về những trận động đất trước – có thể nhận ra rất nhiều kiểu tín hiệu thuộc nhiều loại chấn động khác nhau, điều mà phương pháp cũ khó làm được.
Học máy giờ phổ biến đến mức nhiều bài báo khoa học không còn ghi chữ “machine learning” ngay ở tiêu đề nữa, Mousavi nói: “Ngầm hiểu là ai cũng biết rồi.”
Theo ông, AI không chỉ nhanh hơn con người trong phase picking, mà độ chính xác ít nhất cũng tương đương. Và các nhà địa chấn đang tìm cách mở rộng những công cụ này sang nhiều dạng phân tích địa chấn khác.
[block id=”related-post”]
Mở rộng “sổ tay động đất”: từ bản phác đến bản đồ siêu chi tiết
Một lĩnh vực đã chứng kiến bước nhảy vọt rõ rệt là mở rộng các catalog động đất – tức “sổ ghi chép” về các trận động đất đã xảy ra ở một vùng nào đó.
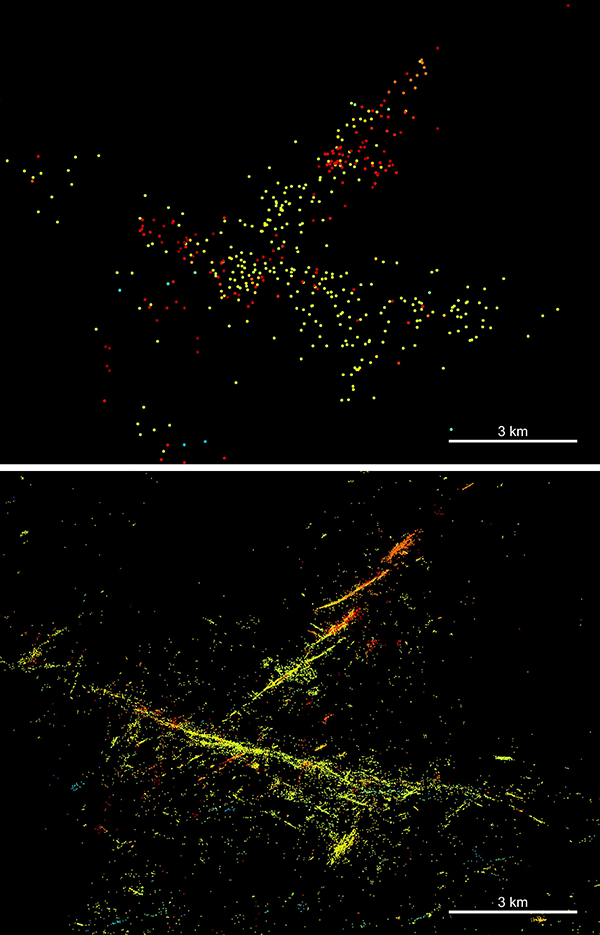
Catalog động đất liệt kê tất cả các trận động đất mà nhà khoa học có thể nhận ra từ dữ liệu thu được. Nhưng với AI, người ta bắt đầu tìm ra số lượng chấn động nhiều gấp… bội lần so với trước.
Về bản chất, học máy có thể “cày” qua dữ liệu để tìm ra những trận động đất nhỏ tới mức con người không có thời gian hoặc khả năng nhận ra bằng mắt thường. “Hoặc là bạn không nhìn thấy chúng, hoặc là đơn giản là không có thời gian để xem hết hàng ngàn, hàng triệu sự kiện nhỏ xíu ấy,” Leila Mizrahi, nhà địa chấn học tại ETH Zürich, giải thích. Thường thì các chấn động nhỏ bị che lấp trong “tiếng ồn” của dữ liệu.
Một nghiên cứu tiên phong đăng trên tạp chí Science năm 2019 đã dùng một thuật toán AI đối chiếu mẫu sóng địa chấn, từ đó phát hiện hơn 1,5 triệu trận động đất mini ở Nam California trong giai đoạn 2008–2017 mà trước đó chưa ai biết. Đó là những sự kiện nhỏ đến mức hầu hết mọi người đứng ngay phía trên cũng không cảm nhận được. Nhưng với các nhà địa chấn, việc biết chúng tồn tại lại cực kỳ quan trọng để hiểu “thói quen hoạt động” của một đứt gãy.
Đặc biệt, Mousavi cho rằng những trận động đất rất nhỏ này là “cửa sổ” cho thấy cách các trận động đất lớn bắt đầu. Các trận động đất mạnh trên một đứt gãy có thể chỉ xuất hiện một lần trong cả trăm năm – thời gian quá dài để chúng ta có đủ quan sát chi tiết về quá trình đứt gãy. Trong khi đó, các chấn động nhỏ có cơ chế tương tự, nhưng xảy ra thường xuyên hơn rất nhiều.
Bằng cách nghiên cứu mô hình hoạt động của vô số chấn động nhỏ trong các catalog mở rộng này, các nhà khoa học hy vọng hiểu rõ hơn “cú khởi động” của một trận động đất lớn. Nhờ đó, những catalog phong phú hơn “có tiềm năng giúp chúng ta hiểu và mô hình hóa rủi ro địa chấn tốt hơn,” Mousavi nói.
Catalog mở rộng cũng giúp vẽ lại cấu trúc đứt gãy dưới lòng đất chi tiết hơn nhiều. Nếu trước đây chúng ta chỉ có một bản phác thảo đơn giản, thì bây giờ là một bức tranh gần như “chụp ảnh” cấu trúc thật.
Năm 2022, nhóm của nhà địa chấn học Yongsoo Park (khi đó ở Stanford) đã dùng học máy để xây dựng catalog động đất ở Oklahoma và Kansas trong giai đoạn 2010–2019, phần lớn là các trận động đất do hoạt động bơm nước thải của ngành dầu khí gây ra.
Kết quả cho thấy các cấu trúc đứt gãy hiện ra rõ ràng hơn, giúp họ vẽ lại bản đồ đứt gãy chính xác hơn và hiểu rõ hơn về rủi ro địa chấn tại đây. Park và đồng nghiệp phát hiện 80% các trận động đất lớn xảy ra trong vùng có thể được “dự đoán” từ mô hình của các chấn động nhỏ trước đó.
“Luôn có khả năng trận động đất lớn tiếp theo sẽ xảy ra trên một đứt gãy mà chúng ta chưa hề lập bản đồ,” Park (nay làm việc tại Phòng thí nghiệm Quốc gia Los Alamos, Mỹ) nói. “Việc ghi lại thường xuyên các chấn động nhỏ có thể giúp lộ ra những đứt gãy ẩn này trước khi một trận động đất lớn xảy ra.”
Cách tiếp cận này đang được áp dụng khắp thế giới.
Tại Đài Loan, sau trận động đất mạnh 7,3 độ vào tháng 4/2024 khiến ít nhất 18 người thiệt mạng và làm hư hại hàng trăm công trình, các nhà nghiên cứu đã dùng học máy để xây dựng một catalog chi tiết hơn. Công trình, được báo cáo tại một hội nghị địa chấn tháng 4/2025, cho thấy catalog do AI xây dựng hoàn chỉnh gấp khoảng 5 lần catalog do con người lập – và nó chỉ mất… một ngày, thay vì vài tháng như cách làm truyền thống.
Catalog này hé lộ nhiều chi tiết mới về vị trí và hướng của các đứt gãy – thông tin rất cần thiết để chính quyền chuẩn bị tốt hơn cho những kịch bản rung lắc trong tương lai. “Những dạng catalog này sẽ trở thành tiêu chuẩn ở tất cả các vùng dễ xảy ra động đất,” nhà địa chấn Hsin-Hua Huang (Academia Sinica, Đài Loan), trưởng nhóm nghiên cứu, nhận định.
Dự báo vẫn là bài toán khó
Dù rất hữu ích trong việc phân tích dữ liệu quá khứ, AI vẫn chưa tạo ra bước đột phá trong một bài toán “khó nhằn” nhất của địa chấn học: dự báo tương lai.
Dự báo động đất không phải kiểu “ngày X sẽ có trận động đất Y” như dự báo thời tiết. Thay vào đó, nó cung cấp xác suất: ví dụ, khả năng xảy ra một trận động đất trên 7 độ Richter tại vùng Z trong 30 năm tới là bao nhiêu phần trăm.
Hiện tại, các dự báo này dựa trên phân tích thống kê: xem các trận động đất trước đã kích hoạt nhau như thế nào, tần suất ra sao… Phương pháp này đủ tốt cho một số nhiệm vụ cụ thể, chẳng hạn ước tính số lượng dư chấn sẽ xảy ra sau một trận động đất lớn. Thông tin đó có thể giúp người dân trong vùng thảm họa quyết định xem đã an toàn để quay lại nhà chưa, hay vẫn còn nguy cơ dư chấn lớn đủ sức làm sập thêm các công trình bị hư hại.
Nhưng những mô hình này không phải lúc nào cũng “bắt trúng” rủi ro thật, nhất là ở các đứt gãy hiếm khi xảy ra động đất lớn nên dữ liệu lịch sử rất nghèo.
Các nhà khoa học đang thử nghiệm những thuật toán dự báo dựa trên AI, hy vọng chúng sẽ làm tốt hơn. Nhưng cho tới nay, kết quả không mấy ấn tượng. Trong những trường hợp tốt nhất, mô hình học máy cho kết quả xấp xỉ các phương pháp truyền thống, chứ chưa vượt trội. “Chúng vẫn chưa đánh bại được các phương pháp cổ điển,” Mousavi nói. Ông đã tóm lược tình hình này trong một bài báo trên Physics Today tháng 8/2025.
Một trong những thử nghiệm hứa hẹn là nghiên cứu của Mizrahi nhằm tăng tốc việc tạo bản đồ dự báo dư chấn trong những phút, những giờ đầu tiên sau một trận động đất lớn.
Cô và đồng nghiệp huấn luyện một mô hình học máy dựa trên chính phương pháp thống kê cũ, rồi để AI tự “chạy” dự báo. Kết quả: mô hình AI cho ra dự báo nhanh hơn rất nhiều, nhưng vẫn còn nhiều chi tiết cần kiểm tra và tinh chỉnh. “Chúng tôi vẫn đang đánh giá xem mức độ hài lòng với nó tới đâu,” Mizrahi nói. Nghiên cứu này được công bố năm ngoái trên tạp chí Seismological Research Letters.
Trong tương lai, các nhà khoa học hy vọng có thể tiếp tục rút ngắn thời gian xử lý cho những dạng phân tích dự báo như vậy. Một số lĩnh vực khác của địa chấn học cũng có thể hưởng lợi: một vài nghiên cứu ban đầu gợi ý học máy có thể dùng cho hệ thống cảnh báo sớm động đất, để ước tính chính xác hơn mức độ rung lắc trong những giây ngay sau khi trận động đất vừa khởi phát gần đó.
Tuy nhiên, lợi ích này hiện chỉ áp dụng cho một số ít nơi đã có hệ thống cảnh báo sớm, như California hay Nhật Bản.
Không phải “cây đũa thần”
Park cũng cảnh báo rằng không nên phó thác quá nhiều cho công cụ học máy. Các nhà khoa học vẫn phải duy trì những quy trình kiểm soát chất lượng nghiêm ngặt, để đảm bảo họ hiểu đúng những gì mô hình AI “nhổ ra”. Dữ liệu nhiều hơn và xử lý nhanh hơn là tốt, nhưng nếu diễn giải sai kết quả, mọi thứ vẫn có thể đi chệch hướng.
Dù vậy, cái nhìn chung trong cộng đồng địa chấn học vẫn rất lạc quan. AI đang giúp họ nghe Trái đất “nói” rõ hơn, dày đặc hơn, chi tiết hơn; vẽ lại mạng lưới đứt gãy dưới chân mình sắc nét hơn; và từng bước hiểu rõ hơn cơ chế của những rung chuyển có thể tàn phá cả một thành phố.
“Chúng ta đang trên đường đi tới đó,” Mizrahi nói. “AI chưa giải được mọi bài toán, nhưng nó đã mở cho chúng ta một chân trời hoàn toàn mới trong việc hiểu về động đất.”








