

Các nhà khoa học đang nghiên cứu các thuật toán, phần cứng và phương pháp tính toán mới nhằm giảm nhu cầu tiêu thụ điện của AI. Việc quy hoạch vị trí đặt các trung tâm dữ liệu một cách chiến lược cùng các biện pháp tăng cường sử dụng năng lượng xanh cũng là những yếu tố then chốt.
Tác giả: Katarina Zimmer
Khi tôi đang nhâm nhi tách cà phê trong căn hộ ở Berlin và đặt một câu hỏi cho chatbot AI Gemini của Google, thật dễ để ngó lơ lượng năng lượng cần thiết để tạo ra câu trả lời đó. Tôi hình dung, ngay khi tín hiệu chạm tới bộ định tuyến (router) của mình, nó sẽ truyền vút qua các đường dây đồng hoặc cáp quang để đến một trong những trung tâm dữ liệu của Google. Đâu đó bên trong những dãy hành lang như mê cung với hàng chồng bộ vi xử lý xếp san sát, câu hỏi của tôi được chuyển hóa thành các con số và trải qua hàng tỷ phép tính để phân tích ngữ cảnh và ý nghĩa. Câu trả lời sau khi được tổng hợp sẽ lao vút trở lại chỉ trong một chớp mắt.
Các trung tâm dữ liệu – vốn được coi là “trái tim” của mạng Internet, vận hành mọi thứ từ email đến tìm kiếm web – đã tồn tại hàng thập kỷ qua. Nhưng với sự bùng nổ của AI tạo sinh trong việc tạo văn bản, hình ảnh và video, chúng đang ngốn nhiều năng lượng hơn bao giờ hết. Theo ước tính của chính Google, việc xử lý một câu lệnh văn bản có độ dài trung bình bằng trợ lý AI Gemini tiêu tốn khoảng 0,24 watt-giờ.
Con số này nếu xét riêng lẻ thì rất nhỏ — 0,24 watt-giờ chỉ tương đương với lượng điện xem TV trong khoảng 9 giây — nhưng chúng lại đang tích tụ với tốc độ chóng mặt. Vào tháng 3 năm 2026, OpenAI ước tính có hơn 900 triệu người sử dụng chatbot AI ChatGPT mỗi tuần, tạo ra hàng tỷ lượt truy vấn mỗi ngày.

Eric Masanet, nhà nghiên cứu về tính bền vững của trung tâm dữ liệu tại Đại học California, Santa Barbara, cho biết lượng điện tiêu thụ chính xác của các trung tâm dữ liệu trên toàn cầu hoặc tại Hoa Kỳ (nơi đặt nhiều trung tâm dữ liệu nhất thế giới) không được tất cả các công ty công nghệ công bố rộng rãi. Tuy nhiên, theo các ước tính gần đây nhất của Cơ quan Năng lượng Quốc tế (IEA), các trung tâm dữ liệu tại Mỹ đã ngốn khoảng 224 terawatt-giờ điện vào năm 2025 — chiếm hơn 5% tổng lượng điện tiêu thụ của cả nước. Đây là một bước nhảy vọt đáng kể so với mức ước tính 1,9% vào năm 2018, thời điểm trước khi AI tạo sinh trở thành làn sóng phổ biến.
Mức tiêu thụ điện này dường như sẽ còn tăng phi mã. Trong cuộc đua giành vị trí dẫn đầu thị trường cho các sản phẩm AI tạo sinh, các ông lớn như Google, Meta, Amazon, OpenAI, Anthropic, Microsoft và Oracle đang đầu tư từ hàng chục đến hàng trăm tỷ đô la để xây dựng các trung tâm dữ liệu chuyên dụng cho AI. So với các trung tâm dữ liệu thời tiền AI vốn tiêu thụ khoảng 100 megawatt điện — đủ để cấp điện cho 83.000 hộ gia đình có mức nhu cầu trung bình — các “tân binh” này thường có quy mô siêu lớn (hyperscale) và có thể ngốn từ 1 gigawatt trở lên, tương đương khoảng 1/10 công suất điện của toàn thành phố Los Angeles.
Masanet và các chuyên gia khác không khỏi lo ngại khi thấy phần lớn nhu cầu năng lượng này đang được đáp ứng bởi các nhà mạng lưới điện chạy bằng nhiên liệu hóa thạch, chẳng hạn như khí đốt – vốn giải phóng khí nhà kính $CO_2$ làm Trái Đất nóng lên khi đốt cháy. Lý do cốt lõi là các trung tâm dữ liệu thường được xây dựng ở những nơi thiếu thốn nguồn năng lượng tái tạo dồi dào như thủy điện, địa nhiệt, điện mặt trời hoặc điện gió.
Các công ty công nghệ thường bù đắp lượng khí thải bằng cách đầu tư vào năng lượng tái tạo ở những nơi khác. Tuy nhiên, trừ khi các nhà máy năng lượng sạch đó tạo ra nhiều năng lượng hơn mức các trung tâm dữ liệu tiêu thụ, chiến lược này — trong trường hợp tốt nhất — cũng chỉ giữ cho lượng khí thải $CO_2$ của các trung tâm ở trạng thái đóng băng chứ không thể giảm chúng về mức bằng không (phát thải ròng bằng 0), một mục tiêu quan trọng để ngăn chặn tình trạng nóng lên toàn cầu. “Cứ mỗi megawatt điện từ nhiên liệu hóa thạch mà chúng ta lắp đặt,” Masanet nói, “tiến trình của chúng ta lại bị thụt lùi.”
Và đó là chưa tính đến các nguồn lực tiêu tốn cho việc sản xuất phần cứng lắp đặt trong các trung tâm dữ liệu mới, hay những tác động lên các cộng đồng sống gần đó — những nơi thường phải gánh chịu ô nhiễm không khí và tiếng ồn từ các nhà máy điện khí, cũng như nguy cơ cạn kiệt nguồn nước địa phương dùng để làm mát các trung tâm dữ liệu này.
Mặc dù việc dự báo tác động năng lượng của AI vẫn cực kỳ nan giải, đặc biệt là khi hiệu quả sinh lời từ các khoản đầu tư vào AI vẫn chưa chắc chắn, các chuyên gia đều thống nhất rằng các chiến lược tiết kiệm năng lượng đang là nhu cầu cấp bách. Nếu không có chúng, theo một ước tính vào năm 2025, các trung tâm dữ liệu tại Mỹ có thể sớm thải ra lượng khí thải tương đương 24 đến 44 megaton $CO_2$ mỗi năm, trong đó con số sau tương đương với lượng khí thải hàng năm của cả đất nước Na Uy.
Chính vì vậy, các nhà khoa học máy tính và kỹ sư đang tái thiết kế lại các phần cứng và phần mềm ngốn điện vốn là nền tảng của AI. Họ đang nỗ lực phát triển các thuật toán và thiết kế bộ vi xử lý tiết kiệm năng lượng, đồng thời cân nhắc kỹ lưỡng về địa điểm và cách thức xây dựng các trung tâm dữ liệu.
“Chi phí năng lượng của AI không phải là một sự cố ngẫu nhiên: Về cơ bản, đây là hệ quả từ cách các hệ thống của chúng ta được xây dựng,” Fengqi You, chuyên gia về hệ thống năng lượng tại Đại học Cornell cho biết. Tuy nhiên, ông nói thêm rằng với sự kết hợp đúng đắn của các giải pháp, “chúng ta thực sự có thể xoay chuyển cục diện này.”
Gốc rễ bài toán năng lượng của AI
Để hình dung được chi phí năng lượng của AI, trước hết cần hiểu về các mô hình ngôn ngữ lớn (LLM) — “mạch máu” của các công cụ tạo văn bản AI như chatbot và trợ lý ảo — cụ thể là những mô hình dựa trên thiết kế được phòng thí nghiệm học máy Google Brain công bố vào năm 2017. Thiết kế này, được gọi là kiến trúc transformer (mô hình máy biến thế), có thể xử lý văn bản với tốc độ ánh sáng bằng cách tiếp nhận đồng thời từng từ và phân tích mối quan hệ của từ đó với mọi từ khác trong câu. Nó “học” xem những từ nào hay đi với nhau bằng cách tính toán mức độ liên kết mạnh mẽ của mỗi từ với tất cả các từ khác trong một đoạn văn, xem xét từng từ trong nhiều ngữ cảnh khác nhau. (Một thiết kế tương tự cũng được áp dụng cho các công cụ tạo hình ảnh và video bằng AI.)
Ở cấp độ tính toán máy tính, quá trình này diễn ra bằng cách chuyển đổi các từ hoặc cụm từ thành các con số và thực hiện các phép tính cộng, nhân giữa chúng. Chìa khóa tạo nên tốc độ nằm ở khả năng thực hiện các phép tính này song song, điều này khả thi nhờ vào các đơn vị xử lý đồ họa (GPU) — chủ yếu do công ty NVIDIA sản xuất — vốn ban đầu được phát minh để dựng hình ảnh 3D nhanh chóng trong trò chơi điện tử.

Giai đoạn huấn luyện ban đầu (training) của một mô hình ngôn ngữ lớn (LLM) nhằm học tất cả các mối quan hệ này tiêu tốn một lượng năng lượng khổng lồ. Bởi vì mỗi từ mà nó được huấn luyện phải được đặt lên bàn cân so sánh với tất cả các từ khác trong một phân đoạn văn bản nhất định, số lượng phép tính mà mô hình thực hiện — và do đó là năng lượng cần thiết — tăng theo hàm mũ bậc hai so với chiều dài của văn bản (nghĩa là chiều dài văn bản tăng gấp đôi thì số lượng phép tính tăng gấp bốn). Con số đó tích tụ rất nhanh khi biết rằng hầu hết các LLM đều được huấn luyện trên các kho dữ liệu văn bản khổng lồ có sẵn trên Internet. Một vài ước tính cho thấy việc huấn luyện GPT-4 — phiên bản ChatGPT ra mắt năm 2023 — đã ngốn từ 50 đến 60 gigawatt-giờ điện, đủ để thắp sáng toàn bộ thành phố San Francisco từ 3 đến 4 ngày.
Tuy nhiên, các chuyên gia lo ngại hơn về chi phí năng lượng khi sử dụng các mô hình này để tạo ra dữ liệu sau khi chúng đã được huấn luyện, một quy trình được gọi là suy luận (inference). “Bạn chỉ huấn luyện một lần, nhưng sau đó bạn thực hiện suy luận cho một tỷ người trên thế giới,” Mosharaf Chowdhury, một chuyên gia hệ thống AI tại Đại học Michigan, người đang đo lường lượng điện tiêu thụ của một số mô hình ngôn ngữ lớn được mở cho công chúng, cho biết.
Quy trình này kém hiệu quả đến mức ngỡ ngàng: Mỗi khi các mô hình transformer tạo ra một từ — bằng cách chọn từ có xác suất xuất hiện cao nhất sau từ trước đó dựa trên ngữ cảnh — chúng lại đẩy câu lệnh và phần câu trả lời đã viết một nửa chạy qua toàn bộ mô hình. Khi làm vậy, chúng áp dụng tất cả các tham số (parameters) mà chúng đã tính toán được trong quá trình huấn luyện để hiểu các cấu trúc ngôn ngữ — con số tham số này lên tới hàng trăm tỷ, thậm chí hàng nghìn tỷ.
“Việc bạn phải thực hiện một khối lượng tính toán khổng lồ chỉ để thêm vào một từ duy nhất — đó là một vấn đề nhức nhối,” Günter Klambauer, một chuyên gia AI tại Đại học Johannes Kepler ở Áo, nhận định.
Tinh chỉnh phần mềm AI để tiết kiệm năng lượng
Nhận thức này đã khơi dậy làn sóng quan tâm đến các mô hình ngôn ngữ nhỏ hơn, được chuyên biệt hóa cho các nhiệm vụ cụ thể. Các mô hình này được huấn luyện trong phạm vi hẹp hơn, có ít tham số hơn — khoảng vài chục hoặc vài trăm triệu — và thực hiện ít phép tính hơn đáng kể so với các mô hình lớn. Trong một bài báo năm 2025 do UNESCO xuất bản, nhà khoa học máy tính Ivana Drobnjak thuộc Đại học College London và các đồng nghiệp đã so sánh mức tiêu thụ năng lượng của mô hình ngôn ngữ Llama-3.1 của Meta với các mô hình AI nhỏ hơn chuyên dùng cho các tác vụ cụ thể — như DistilBART và t5-small-xsum để tóm tắt văn bản, và các mô hình khác dành cho việc dịch thuật hoặc trả lời câu hỏi. Khi được sử dụng đúng tác vụ chuyên môn, các mô hình nhỏ này tiêu thụ năng lượng ít hơn 90% so với Llama 3.1 khi xử lý cùng một công việc.
Để tối ưu hóa, các nhà khoa học máy tính đã tìm cách tích hợp kiểu chuyên môn hóa nhiệm vụ này vào chính các mô hình LLM lớn. Trong các mô hình “hỗn hợp chuyên gia” (mixture of experts), chỉ có các phần cụ thể của một mô hình lớn được kích hoạt cho các tác vụ nhất định. Các phần này “học cách xử lý các cấu trúc ngôn ngữ khác nhau,” Drobnjak giải thích.
Đây được cho là một lý do giải thích tại sao R1, một LLM do công ty DeepSeek của Trung Quốc phát triển, được báo cáo là tiêu thụ năng lượng ít hơn đáng kể so với các mô hình khác (dù các chuyên gia độc lập đã dấy lên nghi ngờ về các số liệu đó). Udit Gupta, một chuyên gia về kỹ thuật điện và máy tính tại Cornell Tech, cho biết các LLM như Gemini hay ChatGPT cũng đang định tuyến các câu hỏi của người dùng đến các mô hình phụ chuyên biệt hơn theo cách tương tự. “Có rất nhiều nghiên cứu đang được thực hiện về cách đánh giá độ phức tạp của câu lệnh hoặc tác vụ từ người dùng, từ đó tìm ra mô hình phù hợp nhất,” Gupta nói. (Mặc dù người phát ngôn của Google, Ralf Bremer, lưu ý rằng mức 0,24 watt-giờ hiện tại để xử lý các câu lệnh Gemini có độ dài trung bình đã hiệu quả gấp 33 lần so với năm 2024, một số chuyên gia vẫn nghi ngờ rằng việc xử lý câu hỏi bằng LLM vẫn tốn năng lượng hơn một lượt tìm kiếm web tương đương.)
Các nhà khoa học cũng đang khám phá các loại LLM khác nhau để phá bỏ cái gọi là “lời nguyền hàm mũ” của các mô hình transformer như Klambauer đề cập.
Một giải pháp thay thế, được gọi là mô hình bộ nhớ dài-ngắn hạn (LSTM), giúp né tránh sự gia tăng năng lượng đáng ngại này bằng cách lưu trữ tạm thời một dạng bản tóm tắt của câu lệnh đầu vào cùng với đoạn văn bản đã được tạo ra cho đến thời điểm đó, tương tự như việc nhớ các tình tiết chính của cốt truyện thay vì phải nhớ từng khung hình của cả bộ phim. Bằng cách đó, mỗi khi tạo ra một từ mới, nó chỉ phải xử lý bản tóm tắt thay vì toàn bộ các từ trong văn bản trước đó. Điều này giúp chi phí năng lượng của LSTM không bị tăng phi mã khi phản hồi một câu hỏi — giúp tiết kiệm khoảng 50% năng lượng so với các mô hình kiểu transformer khi xử lý các văn bản có độ dài khoảng 8.000 từ, Klambauer cho biết.
Các mô hình LSTM từng được phát triển vào những năm 1990 nhưng bị bỏ xó vì các mô hình transformer có thể huấn luyện nhanh hơn nhiều. Tuy nhiên, Klambauer cho biết những tiến bộ gần đây đã cải thiện hiệu suất của LSTM, hiện được gọi là xLSTM. Ông đang hợp tác với công ty khởi nghiệp NXAI của Áo để phát triển và tối ưu hóa thêm xLSTM, “bởi vì chúng tôi nghĩ rằng nó thực sự xứng đáng xét về khía cạnh hiệu quả năng lượng,” ông nói.
Dù vậy, các tập đoàn công nghệ lớn đã đầu tư quá nhiều năm và tài nguyên vào việc phát triển các mô hình dựa trên transformer, nên việc chuyển sang các mô hình khác sẽ rất tốn kém, Wolfgang Maaß, một nhà nghiên cứu AI và tin học kinh doanh tại Trung tâm Nghiên cứu Trí tuệ Nhân tạo Đức, nhận định. “Chúng ta phải chờ xem liệu mô hình này có trở nên thống trị hay không, hoặc liệu nó có tìm được một thị trường ngách trong toàn bộ hệ sinh thái.”
Điện toán bằng đĩa bán dẫn và ánh sáng
Mặc dù các chuyên gia nhận định việc tiết kiệm năng lượng nhanh nhất sẽ đến từ những tinh chỉnh phần mềm, một số người cũng đang nhắm thẳng vào các chip xử lý ngốn điện. Theo thời gian, các kỹ sư đã giúp chip ngày càng hiệu quả hơn bằng cách nén nhiều năng lực tính toán hơn vào các bộ vi xử lý riêng lẻ — giúp giảm năng lượng cần thiết để trung chuyển dữ liệu giữa các chip đang phối hợp với nhau nhằm thực hiện các phép tính AI. Các kỹ sư làm được điều này bằng cách thu nhỏ kích thước của các bóng bán dẫn (transistors) — những công tắc điện siêu nhỏ xử lý dữ liệu — bên trong các con chip.
Tuy nhiên, vì các kỹ sư đang chạm tới các giới hạn vật lý của việc thu nhỏ bóng bán dẫn, “chúng ta cần nghĩ đến các ý tưởng thay thế để cải tiến thiết kế,” kiến trúc sư máy tính Ajay Joshi tại Trung tâm Quang điện tử Đại học Boston cho biết.
Một chiến lược là làm cho các con chip lớn hơn. “Chip quy mô đĩa bán dẫn” (wafer-scale chips) có kích thước bằng một chiếc đĩa ăn có thể chứa số lượng bóng bán dẫn gấp gần 70 lần so với một GPU có kích thước bằng con tem bưu chính, và tiêu thụ điện cho việc truyền thông tin ít hơn 143 lần so với các GPU tương đương, Rakesh Kumar, kỹ sư máy tính tại Đại học Illinois Urbana-Champaign, cho biết. Được sản xuất thương mại bởi công ty Cerebras của California, chip quy mô đĩa bán dẫn có những nhược điểm, bao gồm nguy cơ lỗi hỏng cao hơn trong quá trình sản xuất. Nhưng nhờ tính năng tiết kiệm năng lượng và các ưu điểm khác, “chúng sẽ rất hấp dẫn đối với nhiều nhà cung cấp dịch vụ đám mây siêu lớn và các công ty AI,” Kumar nói.

Nhiều công ty công nghệ đã cải thiện hiệu quả năng lượng bằng cách tự thiết kế các bộ vi xử lý tùy chỉnh “đo ni đóng giày” cho các phép tính AI — chẳng hạn như chip Trainium2 của Amazon Web Service hay các Bộ xử lý Tensor Ironwood của Google — theo tuyên bố từ các công ty này. Về phía NVIDIA, Josh Parker, người đứng đầu bộ phận bền vững của công ty, cho biết các GPU chuyên dụng cho AI của họ đã tiến một bước dài so với các dòng chip dùng cho chơi game trước đây và hiện được thiết kế để chạy các tác vụ AI một cách hiệu quả nhất có thể; các cải tiến khác, chẳng hạn như làm cho kết nối giữa các GPU hiệu quả hơn, cũng đóng góp một phần lớn. “Trong 8 năm qua, các GPU của NVIDIA đã cải thiện gấp 45.000 lần về hiệu quả năng lượng cho các khối lượng công việc của mô hình ngôn ngữ lớn,” ông nói.
Các kỹ sư cũng đang khám phá các phương pháp điện toán thay thế. Các bộ xử lý AI truyền thống tính toán bằng cách mã hóa các con số trong hệ thống nhị phân gồm các số 1 và số 0, đạt được bằng cách bật và tắt các bóng bán dẫn (ví dụ: để biểu thị số 5, cần 4 bóng bán dẫn để thể hiện mã 0101). Nhưng các bóng bán dẫn có thể làm được nhiều hơn là chỉ hoạt động như các công tắc nhị phân cho phép dòng electron chạy qua hoặc không; chúng cũng có thể hoạt động như các nút xoay vô cấp (analog) và giữ các mức điện áp trung gian đại diện cho các con số khác nhau. Điều đó đòi hỏi ít bóng bán dẫn hơn và ít năng lượng hơn cho các phép tính. “Mọi người đã biết từ nhiều thập kỷ trước rằng việc thực hiện một số việc theo dạng analog… có thể tiết kiệm năng lượng hơn rất nhiều,” Kumar nói.
Ví dụ, kỹ sư điện Paul Manea thuộc viện nghiên cứu Forschungszentrum Jülich của Đức và các đồng nghiệp đang nỗ lực phát triển các thiết bị gọi là “tế bào khuếch đại” (gain cells) chứa đầy các bóng bán dẫn hoạt động theo cách này. Quan trọng là, các tế bào khuếch đại có thể vừa lưu trữ dữ liệu cần thiết để xử lý câu hỏi, vừa tính toán ra câu trả lời. Điều đó khắc phục được một nút thắt cổ chai năng lượng lớn khác của các hệ thống máy tính truyền thống, nơi bộ nhớ lưu trữ và bộ phận tính toán nằm trên các phần cứng riêng biệt.
Điều đó đặc biệt rắc rối đối với các LLM dựa trên transformer, bởi vì mỗi khi tạo ra một từ, chúng phải trung chuyển câu hỏi và câu trả lời đã viết một nửa từ bộ nhớ sang bộ vi xử lý. Manea và các đồng nghiệp ước tính rằng việc sử dụng các tế bào khuếch đại thay cho các GPU truyền thống có thể giảm lượng năng lượng bị ngốn bởi một trong những phần ngốn điện nhất của LLM dựa trên transformer xuống 10.000 lần (bốn bậc đại lượng). Tuy nhiên, sẽ cần tinh chỉnh thêm trước khi chúng có thể được sử dụng rộng rãi hơn, Manea cho biết.
Ý niệm về các thiết bị vừa lưu trữ vừa tính toán thông tin là ý tưởng cốt lõi của điện toán “mô phỏng thần kinh” (neuromorphic computing), một lĩnh vực kỹ thuật máy tính mới nổi được lấy cảm hứng từ bộ não con người, vốn tiêu thụ năng lượng ít hơn máy tính nhiều bậc đại lượng. Một phát minh khác lấy cảm hứng từ bộ não là các con chip mã hóa thông tin không phải dưới dạng các dòng dữ liệu liên tục mà — giống như các tế bào thần kinh của con người — dựa vào thời điểm xuất hiện các “xung” điện áp truyền qua hệ thống. Việc cho phép các bộ phận nghỉ ngơi cho đến khi chúng thực sự cần thiết “có khả năng chuyển hóa thành mức năng lượng thấp hơn,” Eleni Vasilaki, một chuyên gia về học máy lấy cảm hứng từ sinh học tại Đại học Sheffield ở Anh, cho biết.
Maaß, ví dụ, là thành viên của một đội ngũ nhận được khoảng 5,8 triệu đô la từ chính phủ Đức để thử nghiệm các chip mô phỏng thần kinh, cùng các chiến lược khác, nhằm giảm năng lượng cần thiết cho các mô hình AI. Một vài con chip lấy cảm hứng từ bộ não đã có sẵn trên thị trường, nhưng công nghệ này vẫn còn xa mới đủ sức hấp dẫn đối với ngành điện toán phổ thông, Tony Kenyon, chuyên gia điện tử nano tại Đại học College London, người có đội ngũ vừa nhận được 17 triệu đô la từ chính phủ Anh để phát triển điện toán mô phỏng thần kinh, nhận định.
Các nhà khoa học khác đang phát triển các con chip xử lý thông tin không phải bằng các electron mà thông qua sự tương tác của các photon — các hạt ánh sáng — với vật chất (cáp quang, vốn mã hóa và truyền dữ liệu dưới dạng các xung ánh sáng, đang được sử dụng trên toàn thế giới). Với các photon, nhiều thông tin có thể được truyền đi cùng một lúc và các tín hiệu có thể được thay đổi nhanh hơn nhiều, Elena Goi, nhà nghiên cứu điện toán quang học tại Đại học Friedrich Schiller Jena ở Đức, cho biết.
Một vài công ty đã phát triển các con chip có thể thực hiện một số phép tính AI bằng phương pháp quang học, Joshi nói; ông gần đây ước tính rằng việc sản xuất chip quang học có thể tiêu thụ năng lượng ít hơn tới 10 lần so với các con chip truyền thống cùng kích thước. Joshi hy vọng rằng, “trong 10 năm tới, chúng ta sẽ có một giải pháp thực tế có thể triển khai rộng khắp tại các trung tâm dữ liệu.”
Định hình lại quỹ đạo năng lượng của AI
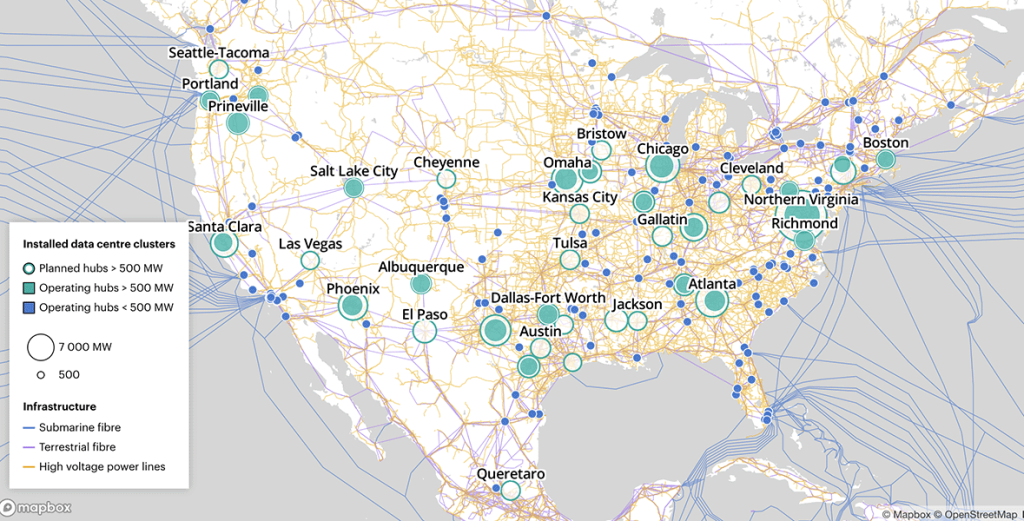
Ngay cả khi không cần phát minh lại cách thức hoạt động của máy tính, người ta vẫn có thể làm được rất nhiều điều để giảm tác động của AI không chỉ đối với năng lượng mà còn đối với nguồn nước dùng để làm mát các trung tâm dữ liệu. Quan trọng là, các công ty công nghệ nên cân nhắc lại nơi họ xây dựng các trung tâm đó, chuyên gia hệ thống năng lượng You nhận định. Hiện tại, các trung tâm dữ liệu hiện có ở Mỹ đang tập trung dày đặc ở phía bắc Virginia, nơi có nguồn nước và công suất năng lượng tái tạo hạn chế so với khu vực Trung Tây, chẳng hạn. You gần đây ước tính rằng việc chọn vị trí đặt trung tâm dữ liệu tốt hơn — cùng với phần cứng và phần mềm tiết kiệm năng lượng — có thể giảm lượng carbon và dấu chân nước (lượng nước tiêu thụ) tương lai của các trung tâm dữ liệu tại Mỹ lần lượt là 73% và 86%.
Masanet nói thêm rằng các công ty công nghệ vốn đã sở hữu các trung tâm dữ liệu trên khắp đất nước ít nhất có thể huấn luyện các mô hình của họ ở những địa điểm chiến lược. “Một số công ty như Google đã và đang làm điều này: Họ dịch chuyển tải công việc của mình để đi theo các nguồn năng lượng tái tạo,” ông nói. Họ cũng nên giải quyết vấn đề điện năng và tài nguyên tiêu tốn cho việc sản xuất các bộ vi xử lý cho các trung tâm dữ liệu mới, cũng như rác thải điện tử khi công nghệ lỗi thời bị thay thế sau mỗi vài năm, ông nói thêm.
Theo một tuyên bố gửi tới Tạp chí Knowable, giảm thiểu rác thải điện tử bằng cách sử dụng phần cứng trong thời gian dài hơn và thu hồi các thiết bị điện tử cũ là một trong những chiến lược bền vững của Amazon; thiết kế các trung tâm dữ liệu theo cách tiết kiệm năng lượng, tiết kiệm nước và đầu tư vào một loạt các dự án năng lượng tái tạo và năng lượng hạt nhân cũng nằm trong chiến lược này. Brandon Oyer, người đứng đầu bộ phận năng lượng và nước của Amazon Web Services tại châu Mỹ, cho biết: “Chúng tôi sẽ tiếp tục triển khai các giải pháp mang lại lợi ích cho khách hàng và các cộng đồng nơi chúng tôi hoạt động.”
Trong khi đó, một đại diện truyền thông tại Microsoft chỉ ra một số sáng kiến bền vững mà công ty đã thực hiện, bao gồm các công nghệ làm mát mới, đầu tư vào năng lượng tái tạo và giảm thiểu chất thải. Người phát ngôn của Google, Ralf Bremer, nhấn mạnh mục tiêu của công ty là đạt mức phát thải ròng bằng không trong toàn bộ hoạt động của mình vào năm 2030 và hoàn trả 120% lượng nước ngọt tiêu thụ bởi các văn phòng và trung tâm dữ liệu của mình vào năm 2030. Một đại diện của OpenAI chỉ ra một thông cáo báo chí vạch ra các nỗ lực nhằm giảm thiểu việc sử dụng nước và kế hoạch sản xuất năng lượng mặt trời tại một trong các khuôn viên của họ. Anthropic, Meta và Oracle đã không phản hồi các yêu cầu bình luận trước thời hạn.
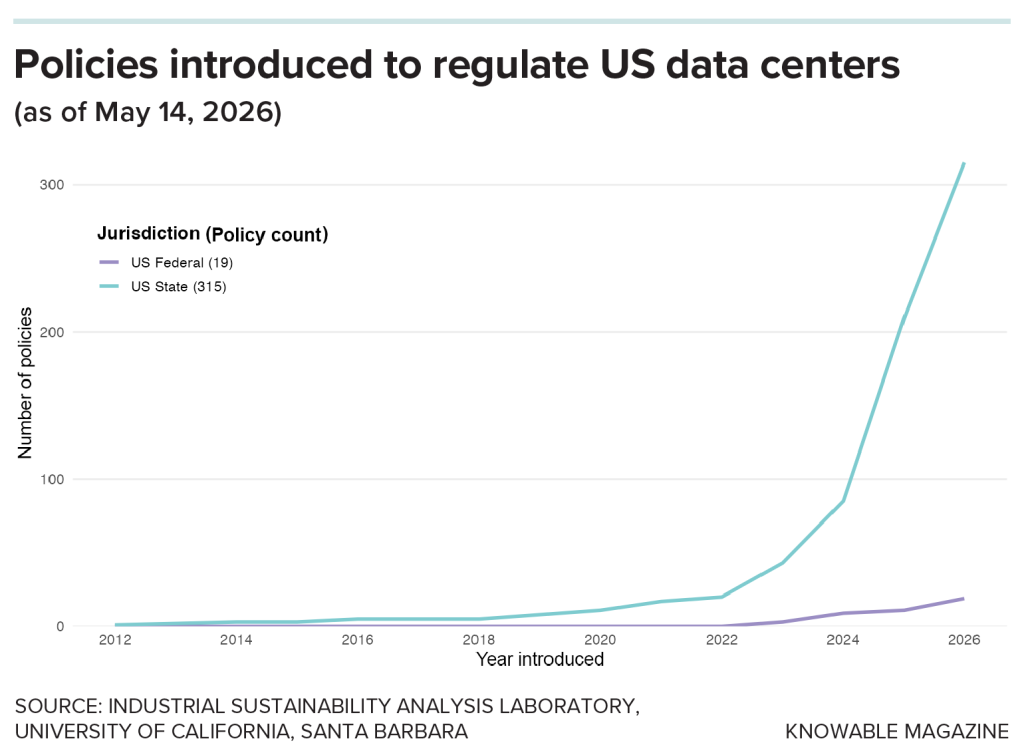
Dù các công ty công nghệ đang xem xét đến tính bền vững, mục tiêu chính của họ vẫn là nhanh chóng mở rộng công suất của các trung tâm dữ liệu, Benjamin Lee, kỹ sư máy tính tại Đại học Pennsylvania, nhận định. Ông dự đoán rằng, rốt cuộc, họ sẽ cần phải đẩy mạnh các nỗ lực cải thiện hiệu quả năng lượng để giảm chi phí. Chính phủ các nước nên giúp đẩy nhanh sự chuyển dịch này, Masanet nói. Cho đến nay, ông và đội ngũ của mình đã đếm được gần 220 chính sách được đưa ra để giải quyết tính bền vững của trung tâm dữ liệu ở cấp bang tại Mỹ, 18 chính sách ở cấp liên bang và nhiều chính sách hơn từ các quốc gia khác, mặc dù không phải tất cả đều được thông qua cuối cùng.
“Rõ ràng là chính phủ các nước trên thế giới đang bắt đầu hành động,” ông nói. Tuy nhiên, ông nói thêm, “chúng ta cũng thấy một số chính quyền bang và địa phương đưa ra các chính sách đề xuất chủ yếu nhằm mục đích khuyến khích và thúc đẩy nhanh việc xây dựng các trung tâm dữ liệu.”
Bài toán chi phí năng lượng của AI suy cho cùng sẽ là một sự cân nhắc nặng nhẹ: Liệu AI có tiết kiệm được nhiều tài nguyên hơn nhờ năng lực giải quyết vấn đề của nó — được triển khai từ việc tìm kiếm phương pháp chữa trị ung thư cho đến cải thiện chuỗi cung ứng logistics — so với lượng năng lượng mà bản thân nó đòi hỏi hay không? Tuy nhiên, mặc dù việc xây dựng một hệ thống AI tiết kiệm, tiết kiệm năng lượng hơn là điều quan trọng, việc xem xét kỹ lưỡng nơi nào thực sự cần đến AI cũng quan trọng không kém, Kenyon nói. Liệu thế giới có thực sự trở thành một nơi tốt đẹp hơn, chẳng hạn, chỉ nhờ có các “trợ lý AI” không phải con người thực hiện việc hỗ trợ khách hàng?
“Tôi nghĩ đó là một sai lầm phổ biến, khi một công nghệ mới xuất hiện, người ta bỗng nhiên nghĩ rằng: ‘À, mọi thứ đều phải áp dụng công nghệ mới đó'”, ông nói. “Cách tiếp cận đó thực sự không mang lại lợi lộc gì cho chúng ta cả.”